
How to Select the Right Open-Source LLM

AI & ML
How to Select the Right Open-Source LLM in 2025
28 Feb, 2025
10 Min read
Navigating Open-Source AI: Finding the Best LLM for Your Needs
The rise of open-source language models like LLaMA, Mistral, and DeepSeek has transformed AI adoption. However, with numerous options available, businesses struggle to determine the best model for their unique requirements.
- Will this LLM handle industry-specific jargon?
- Is it cost-effective for long-term deployment?
- How do licensing rules impact scalability?
Benchmarks alone won’t answer these critical questions. In this guide, we go beyond theoretical performance scores to provide real-world evaluation criteria, cost optimization strategies, and deployment best practices—with insights from Stixor, a leader in AI/ML development services.
Top Open-Source LLMs in 2025
1. Meta’s LLaMA 3.1 & 3.2

Different businesses require different AI capabilities. Below, we compare leading open-source LLMs based on their ideal use cases, strengths, and limitations.
Best for: Llama 3.1 405B – Excelling in complex language tasks, long-form content, multilingual translation, and coding with its 405B parameters and 128k token context window.
Llama 3.2 90B Vision – Offering robust multimodal capabilities for integrated text and image processing, ideal for visual reasoning and captioning.
Limitations:Llama 3.1 demands significant computational resources.
Llama 3.2 faces licensing restrictions in certain regions, including the EU.
Tip: Use LLaMA 3.1 for high-accuracy NLP and 3.2 for vision-integrated AI applications.
2. Mistral-7B

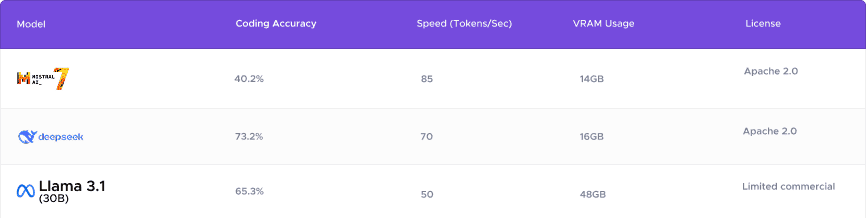
Best for: Low-latency real-time AI applications (85 tokens/sec).
Limitations: Struggles with complex reasoning and non-English languages.
Tip: Pair with retrieval-augmented generation (RAG) to improve accuracy.
3. DeepSeek-67B

Best for: AI-powered coding assistants and technical documentation analysis.
Limitations: Weak performance in creative writing and non-STEM tasks.
Tip: Leverage its 128k token context for summarization-heavy tasks.
4. Alibaba’s Qwen-72B

Best for: Enterprises targeting Chinese-speaking markets and bilingual workflows.
Limitations: Limited open-source fine-tuning support.
Tip: Train on industry-specific datasets (e.g., legal, medical Chinese corpora).
5. Google’s Gemma

Best for: Lightweight AI chatbots and educational applications.
Limitations: Restrictive licensing for finance and healthcare.
Tip: Deploy Gemma-2B on edge devices to optimize resource efficiency.
6. Falcon-40B
Best for: Multilingual AI applications (supports 11 languages).
Limitations: High VRAM consumption (48GB) and lower reasoning accuracy.
Tip: Avoid for latency-sensitive applications—opt for smaller models.

Why Benchmarks Don’t Tell the Full Story
While LLM performance is often measured using benchmarks like MMLU or HumanEval, these scores don’t always translate to real-world success.
Three Key Factors Beyond Benchmarks:
Domain Adaptation: An AI model scoring 90% on general benchmarks may fail when parsing complex legal or medical texts.
Context Window Reality: Despite some models claiming 128k token support, coherence drops beyond 32k tokens in practice.
Hidden Costs: Faster models like Mistral-7B can cut costs by 30%—but may require fine-tuning to reach enterprise-grade accuracy.
How to Evaluate LLMs for Business Applications
Step 1: Define Key Evaluation Criteria
Scale: Enterprise-grade models like LLaMA 3.1 (405B) handle large-scale tasks but require high-end cloud GPUs. Smaller models like Mistral-7B work well for chatbots and AI assistants on local hardware.
Infrastructure Availability: Large models need powerful GPUs (A100, H100) and high VRAM (>80GB), while smaller models (Mistral-7B, Gemma-2B) run on consumer GPUs (RTX 4090, A6000) or edge devices.
Accuracy: Assess with industry-specific benchmarks, such as F1 scores for medical AI, precision/recall for legal AI, and sentiment accuracy for finance AI.
Speed vs. Cost: Higher token speeds (e.g., Mistral-7B: 85 tokens/sec) reduce inference time, while larger models (LLaMA 3.1: 50 tokens/sec) may provide higher accuracy but at increased costs.
Step 2: Real-World Model Testing
Use internal datasets (customer queries, business documents).
Simulate edge cases (ambiguous inputs, multilingual content).
Step 3: Model Comparison Matrix
Key Considerations Beyond Performance
Licensing & Compliance
Apache 2.0 Models (Mistral, Falcon): Free for commercial use.
LLaMA-2: Requires Meta approval for apps with >700M monthly users.
Gemma: Restricted for high-risk industries (finance, healthcare).
Why Choose Stixor for LLM Deployment?
At Stixor, we simplify LLM adoption for businesses by providing:
Pre-Built Evaluation Pipelines: Speed up AI model selection by 50%.
Cost Optimization: Deploy budget-friendly models without sacrificing accuracy.
End-to-End Support: From fine-tuning to scalable deployment.
Schedule a Free Consultation to optimize your AI strategy.
Share with your community!

AI
Adil Gillani
02 Sep, 2025
AI for Mental Health: Continuous Support and Recovery Through Daily Engagement

Regulated AI
Sanan bin Tahir
01 Sep, 2025
AI in Regulated Industries: Lessons from Building a Legal AI - Malakah

MLOps
Sanan bin Tahir
21 Aug, 2025